dissmapr
A Novel Framework for Automated Compositional Dissimilarity and Biodiversity Turnover Analysis
1. Zeta diversity in dissmapr: a
multi-site view of compositional change
Classical β-diversity evaluates how species composition differs between pairs of sites, but many ecological questions, like how wide-ranging species structure whole landscapes, require a perspective that spans three, four or more assemblages at once. Zeta diversity (ζ-diversity) meets this need by counting the number of species jointly shared by i sites (ζ₁, ζ₂, … ζᵢ). As i increases, ζ declines; the shape of that decline summarises how rarity and commonness are distributed across the region. See Guillaume Latombe (2015). zetadiv: Functions to Compute Compositional Turnover Using Zeta Diversity. R package version 1.3.0, https://cran.r-project.org/web/packages/zetadiv. Accessed 30 Jun. 2025.
dissmapr embeds the zetadiv toolkit so
that automated pipelines of compositional dissimilarity can incorporate
higher-order turnover metrics alongside conventional pairwise indices.
Four core functions are central:
-
Expectation of ζ-decline using
Zeta.decline.ex(): Calculates the exact mean ζ for successive orders (ζ₁ … ζₖ) when the site × species matrix is small enough for exhaustive enumeration, giving the theoretical baseline against which observed patterns can be compared function details.
-
Monte-Carlo ζ-decline using
Zeta.decline.mc(): Uses random subsampling to approximate the same decline in large matrices where exhaustive combinations are infeasible, trading a small sampling error for orders-of-magnitude speed-ups function details.
-
ζ distance-decayusing
Zeta.ddecays(): Fits a distance–decay curve for several ζ orders simultaneously, revealing how rapidly shared species drop away with spatial separation and whether higher-order overlap is lost faster or slower than pairwise similarity function details.
-
Multi-site GDM using
Zeta.msgdm(): Extends Generalised Dissimilarity Modelling to multi-site similarity. For a chosen order i it regresses ζᵢ against environmental gradients and geographic distance using GLMs, GAMs or shape-constrained splines, quantifying how each predictor controls the retention of shared species across landscapes function details.
Why this matters for automated turnover analysis
-
Scale-explicit turnover: ζ-decline distinguishes
processes that shape local richness (ζ₁) from those structuring regional
overlap (ζ₄, ζ₅ …), adding nuance to the pairwise β view.
-
Process insight: An exponential ζ-decline
suggests stochastic assembly while a power-law decline implies
niche structure or dispersal limitations.
-
Predictive mapping:
Zeta.msgdm()generates response surfaces for ζᵢ across continuous environmental space, enablingdismaprto project multi-site similarity under current or future scenarios.
-
Integrated workflow: Within
dismaprthe outputs (Zeta.decline.*,Zeta.ddecays(),Zeta.msgdm()) slot directly into the same site-by-environment matrices and raster stacks already produced for GLM/GAM pipelines, ensuring a seamless transition from data wrangling to advanced turnover modelling.
In summary, ζ-diversity counts the species that an entire network of sites share. Imagine moving from one natural area to the next across a region. In the first few nearby places most species still overlap, but as you add more, especially those separated by greater distance or harsher conditions, the list of species found everywhere quickly narrows. ζ-diversity tracks how fast that shared list shrinks, highlighting which species are resilient and widespread versus those confined to only a handful of sites. The faster the shared-species list shrinks, the clearer it becomes which species are robust and occur almost everywhere, and which persist only in a few isolated spots. Viewing many sites at once exposes conservation gaps that simple pairwise comparisons can overlook.
The next sections offer a simple, step-by-step guide to spot where shared biodiversity is weakest and direct protection where it’s needed most.
2. Expectation curve for ζ-diversity decline using
zetadiv::Zeta.decline.ex()
Zeta.decline.ex() calculates the theoretical number of
species that should be shared by 1, 2, … k sites (orders 1–15 here)
using a closed-form formula based solely on each species’ occupancy
frequency. Because no resampling is involved, the output is an exact
expectation of how ζ-diversity ought to fall as more sites are
considered, assuming site identity plays no role. The function also fits
exponential and power-law models to the expected curve, yielding
parameters and fit statistics that provide a baseline against which
observed or Monte-Carlo ζ-decline patterns can be evaluated.
set.seed(123)
zeta_decline_ex = Zeta.decline.ex(grid_spp_pa[,7:ncol(grid_spp_pa)], # Only species columns
orders = 1:15)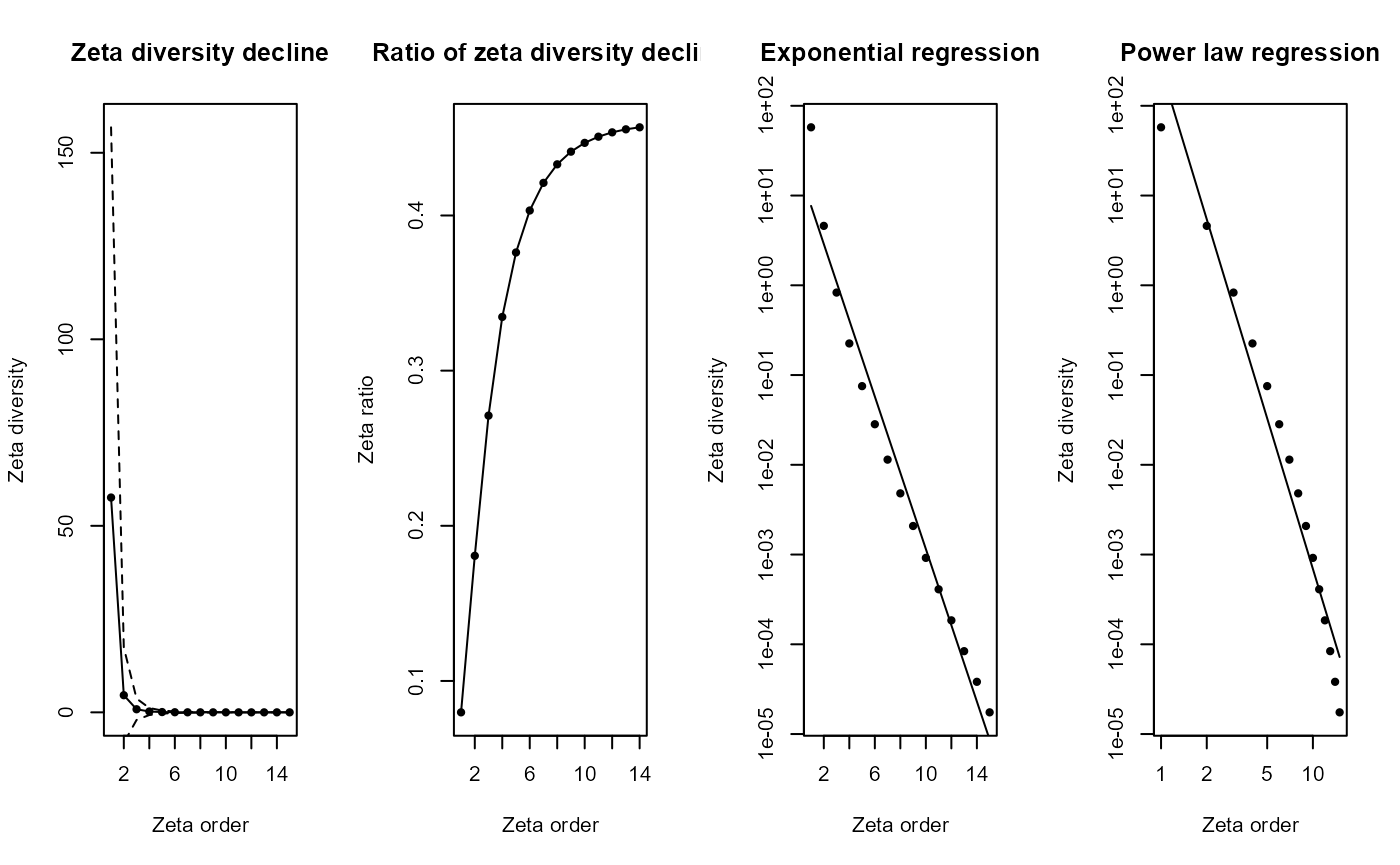
- Panel 1 (Zeta diversity decline): Shows how rapidly species that are common across multiple sites decline as you look at groups of more and more sites simultaneously (increasing zeta order). The sharp drop means fewer species are shared among many sites compared to just a few.
- Panel 2 (Ratio of zeta diversity decline): Illustrates the proportion of shared species that remain as the number of sites compared increases. A steeper curve indicates that common species quickly become rare across multiple sites.
- Panel 3 (Exponential regression): Tests if the decline in shared species fits an exponential decrease. A straight line here indicates that species commonness decreases rapidly and consistently as more sites are considered together. Exponential regression represents stochastic assembly (randomness determining species distributions).
- Panel 4 (Power law regression): Tests if the decline follows a power law relationship. A straight line suggests that the loss of common species follows a predictable pattern, where initially many species are shared among fewer sites, but rapidly fewer are shared among larger groups. Power law regression represents niche-based sorting (environmental factors shaping species distributions).
Interpretation: The near‐perfect straight line in the exponential panel (high R²) indicates that an exponential model provides the most parsimonious description of how species shared across sites decline as you add more sites—consistent with a stochastic, memory-less decline in common species. A power law will also fit in broad strokes, but deviates at high orders, suggesting exponential decay is the better choice for these data.
3. Empirical ζ-diversity decline via Monte-Carlo using
zetadiv::Zeta.decline.mc()
Zeta.decline.mc() estimates how the number of species
shared by 1, 2, … k sites drops when exhaustive combinations are
impractical. It repeatedly draws random sets of sites (Monte-Carlo
sampling), averages the shared-species count for each order, and reports
both the mean and its variability. The resulting curve is then fitted
with exponential and power-law models, providing parameter estimates and
confidence bands that capture real-world turnover while accounting for
sampling uncertainty. In other words, a sharp drop in
the curve means species change quickly from place to place
(communities are unique), while a gentle drop
means many species are found in most places (communities are
similar).
set.seed(123)
zeta_mc_utm = Zeta.decline.mc(grid_spp_pa[,-(1:7)], # Different way to get only species columns
# grid_env[, c("centroid_lon", "centroid_lat")], # WGS84 - decimal degrees
grid_env[, c("x_aea", "y_aea")], # AEA - meters
orders = 1:15,
sam = 100, # Sample size
NON = TRUE,
normalize = "Jaccard")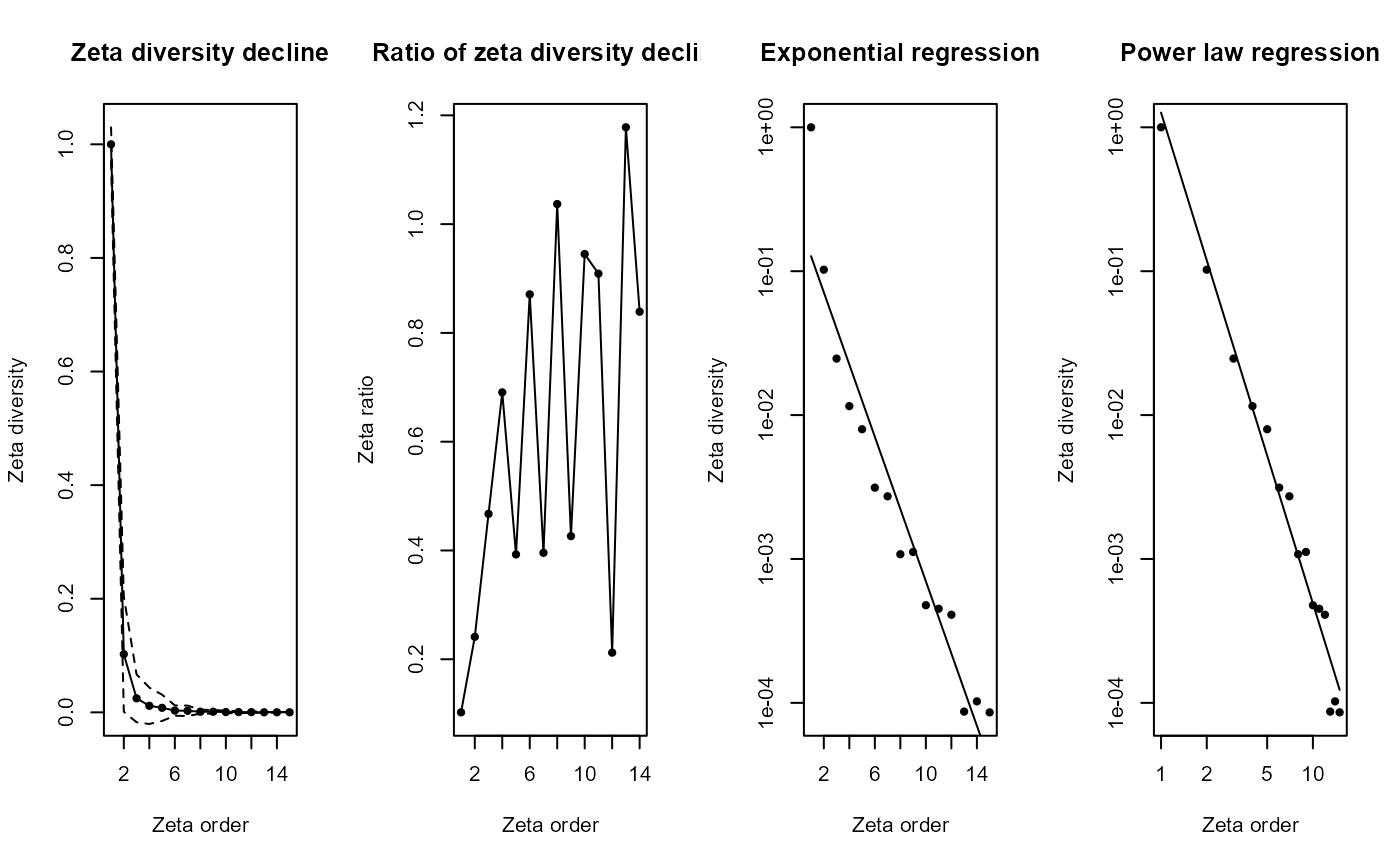
- Panel 1 (Zeta diversity decline): Rapidly declining zeta diversity, similar to previous plots, indicates very few species remain shared across increasingly larger sets of sites, emphasizing strong species turnover and spatial specialization.
- Panel 2 (Ratio of zeta diversity decline): More irregular fluctuations suggest a spatial effect: nearby sites might occasionally share more species by chance due to proximity. The spikes mean certain groups of neighboring sites have higher-than-average species overlap.
- Panel 3 & 4 (Exponential and Power law regressions): Both remain linear, clearly indicating the zeta diversity declines consistently following a predictable spatial pattern. However, the exact pattern remains similar to previous cases, highlighting that despite spatial constraints, common species become rare quickly as more sites are considered.
Interpretation: This result demonstrates clear spatial structuring of biodiversity i.e. species are locally clustered, not randomly distributed across the landscape. Spatial proximity influences which species co-occur more frequently. In practice
Zeta.decline.mc()is used for real‐world biodiversity data—both because it scales and because the Monte Carlo envelope is invaluable when ζₖ gets noisier at higher orders.
4. ζ-diversity distance-decay (orders 2–8) using
zetadiv::Zeta.ddecays()
Zeta.ddecays()measures the drop in shared
species as geographic distance increases. In this example it
evaluates orders 2 through 8 by first binning site
pairs (or groups) into many distance classes, then computing the average
number of species they share in each class, and finally fitting an
exponential distance-decay model via a generalized
linear regression. The function returns the slope and intercept of each
fitted curve, goodness-of-fit statistics, and diagnostic plots that
together show how quickly multisite similarity breaks down with
space at different zeta orders.
# Calculate Zeta.ddecays
set.seed(123)
zeta_decays = Zeta.ddecays(#grid_env[, c("centroid_lon", "centroid_lat")], # WGS84 - decimal degrees
grid_env[, c("x_aea", "y_aea")], # AEA - meters
grid_spp_pa[,-(1:7)],
sam = 1000, # Sample size
orders = 2:8,
plot = TRUE,
confint.level = 0.95
)
#> [1] 2
#> [1] 3
#> [1] 4
#> [1] 5
#> [1] 6
#> [1] 7
#> [1] 8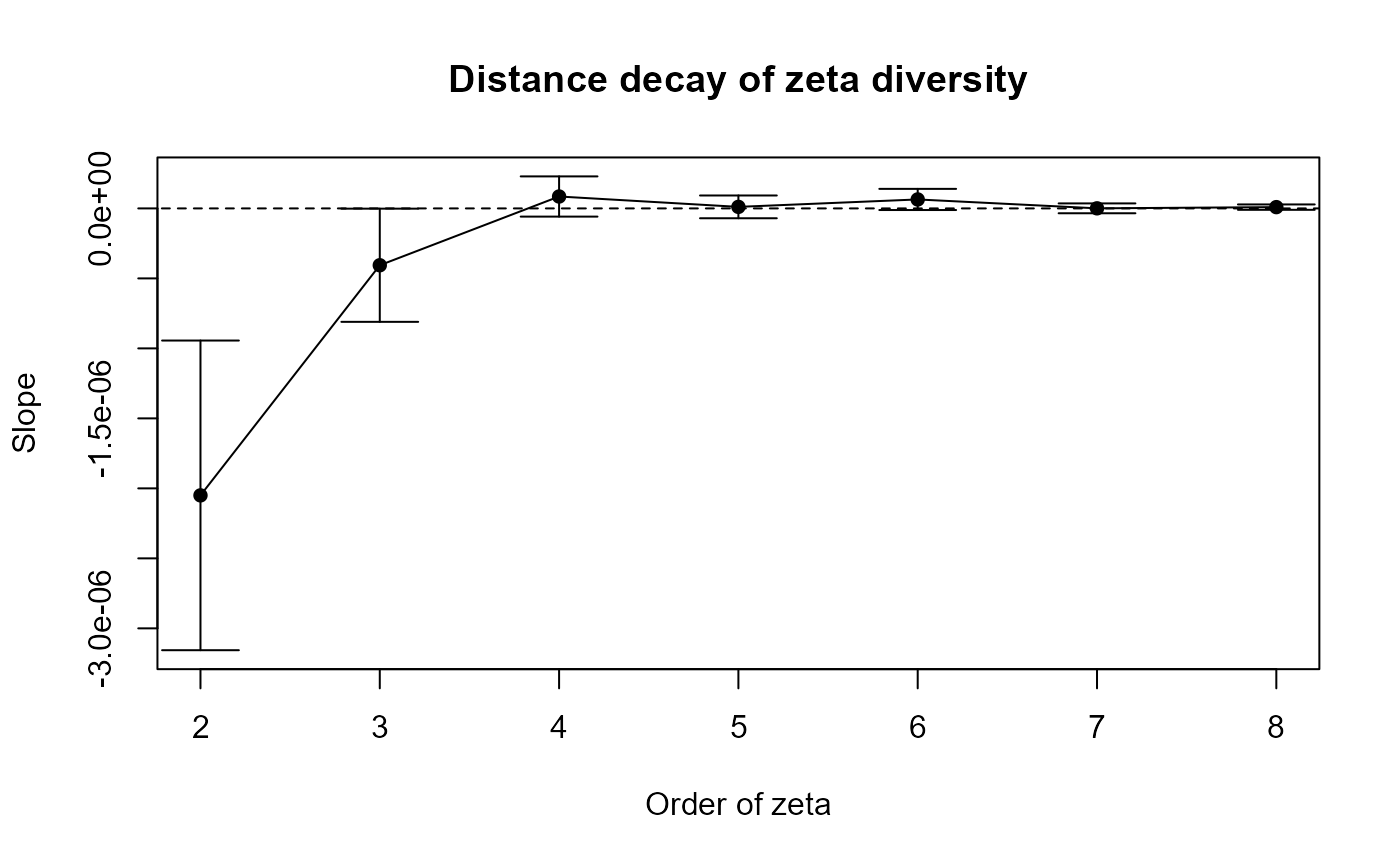
This plot shows how zeta diversity (remember, it’s a metric that captures shared species composition among multiple sites) changes with spatial distance across different orders of zeta (i.e., the number of sites considered at once).
- On the x-axis, we have the order of zeta (from 2 to 8).
For example, zeta order 2 looks at pairs of sites, order 3 at triplets, etc.- On the y-axis, we see the slope of the relationship between zeta diversity and distance (i.e., how quickly species similarity declines with distance).
- A negative slope means that sites farther apart have fewer species in common — so there’s a clear distance decay of biodiversity.
- A slope near zero means distance doesn’t strongly affect how many species are shared among sites.
Interpretation: When you look at just two or three sites, distance really matters because sites far apart share far fewer species, so the decay curve is steep. Once you include four or more sites, that curve flattens out: most widespread species still overlap no matter the distance, so spatial separation has little effect. The tighter confidence bands at higher orders show these broader‐scale patterns are more reliable because they average over many sites. In plain terms, rare or localized species drive strong turnover at small scales, but a core of common species holds communities together across larger regions.
5. Model drivers of compositional turnover with
zetadiv::Zeta.msgdm()
Zeta.msgdm() extends Generalised Dissimilarity
Modelling (GDM) from simple pairwise similarity to any order of
ζ-diversity. Order 2 is, by definition, the pairwise case as it counts
the species shared by two sites. In other words, the results are
directly comparable to conventional β-diversity models. The advantage of
the ζ framework is that you can raise the order (ζ₃, ζ₄, …) with the
same function to reveal higher-order patterns without changing
tools.
Here we fit an order-2 model to ask:
- How strongly do climate, geography, or other predictors control the
chance that two sites share species?
- How does that control change along each environmental gradient?
Zeta.msgdm() proceeds in three
stages:
-
Sampling: draws 1 000 random site pairs
(
sam = 1000) to keep computation tractable.
-
Normalisation: converts order-2 ζ counts to a
Jaccard similarity (
normalize = "Jaccard") so coefficients range between 0 and 1.
-
Regression: fits an I-spline MSGDM
(
reg.type = "ispline") that separates monotonic environmental effects from Euclidean geographic distance (distance.type = "Euclidean").
The fitted model (zeta2) contains partial I-splines for
every predictor (note: higher splines imply stronger turnover per unit
change).
set.seed(246)
# Fit order-2 MSGDM on the presence–absence matrix and reduced covariate set
zeta2 = Zeta.msgdm(
grid_spp_pa[,-(1:7)], # species matrix (rows = sites, cols = spp)
env_vars_reduced, # decorrelated environmental variables
# env_vars_reduced[,-7], # without sampling effort included
grid_env[, c("centroid_lon", "centroid_lat")], # longitude & latitude (°)
# grid_env[, c("x_aea", "y_aea")], # longitude & latitude (meters)
sam = 2000,
order = 2,
distance.type = "Euclidean",
normalize = "Jaccard",
reg.type = "ispline"
)
# Extract and plot the fitted I-splines
# splines = Return.ispline(zeta2, env_vars_reduced[,-7], distance = TRUE) # Without sampling effort
splines = Return.ispline(zeta2, env_vars_reduced, distance = TRUE)
Plot.ispline(splines, distance = TRUE)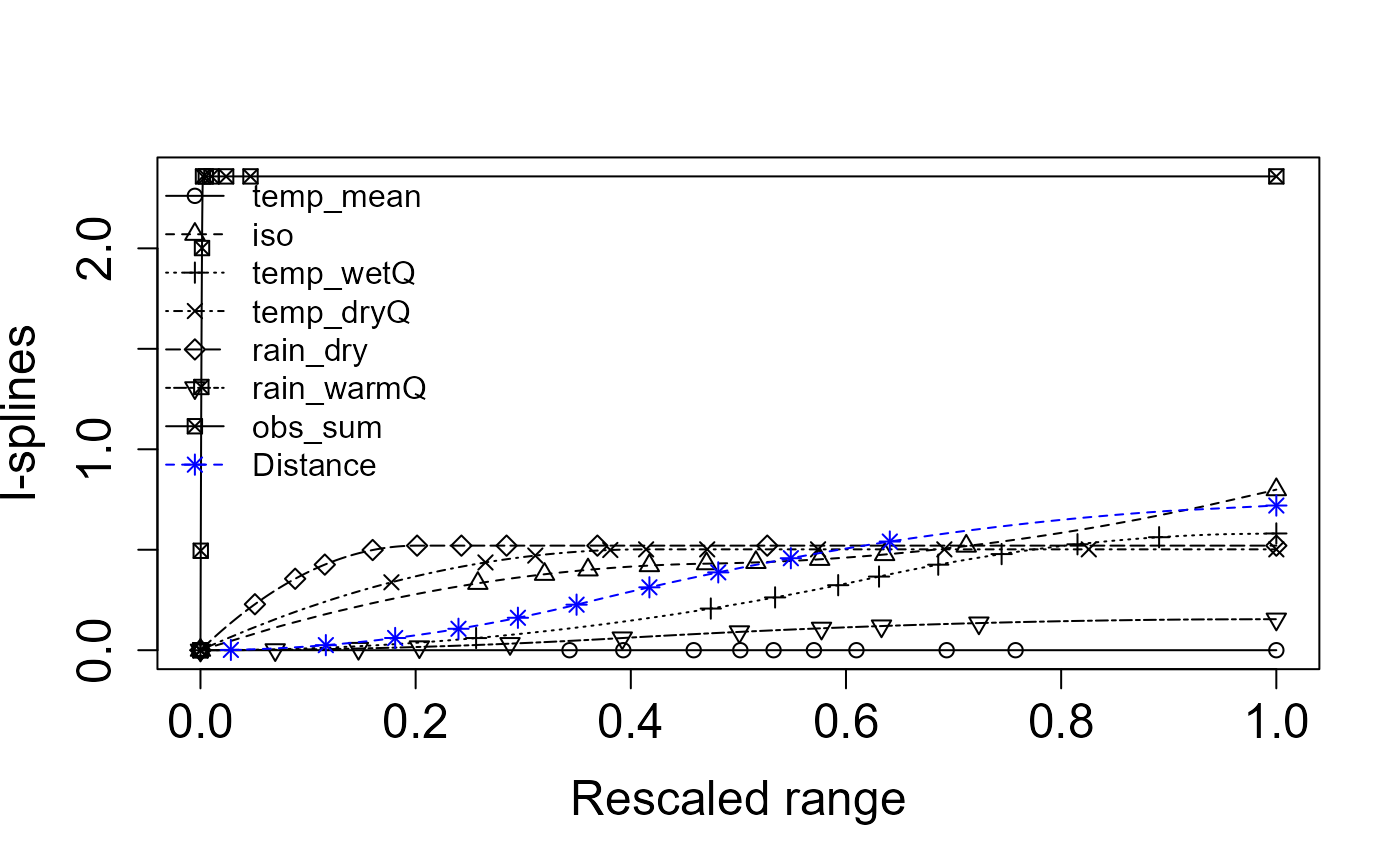
General Interpretation:
-
I-spline height: The taller the curve, the more a
variable drives species turnover.
-
Curve shape: Steep early rises mark thresholds
where small environmental changes cause large compositional shifts;
flatter tails suggest saturation.
- Distance spline: Shows the residual spatial decay once environmental effects are removed, highlighting dispersal limits or unmeasured factors.
By isolating each driver’s effect, this MSGDM pinpoints which gradients most erode shared biodiversity and where management actions could most effectively slow that loss.
Specific Interpretation: This figure shows the fitted I-splines from a multi-site generalized dissimilarity model (via
Zeta.msgdm), which represent the partial, monotonic relationship between each predictor and community turnover (ζ-diversity) over its 0–1 “rescaled” range. A few key take-aways:
- Distance (blue asterisks) has by far the largest I-spline amplitude—rising from ~0 at zero distance to ~0.05 at the maximum. That tells us spatial separation is the strongest driver of multi‐site turnover, and even small increases in distance yield a substantial drop in shared species.
- Sampling intensity (
obs_sum, open circles) comes next, with a gentle but steady rise to ~0.045. This indicates that sites with more observations tend to share more species (or, conversely, that incomplete sampling can depress apparent turnover).- Precipitation variables: Rain in the warm quarter (
rain_warmQ, squares) and Rain in the dry quarter (rain_dry, triangles-down) both show moderate effects (I-spline heights ~0.02–0.03). This means differences in seasonal rainfall regimes contribute noticeably to changes in community composition.- Temperature metrics: Mean temperature (
temp_mean, triangles-up), Wet‐quarter temperature (temp_wetQ, X’s), Dry‐quarter temperature (temp_dryQ, diamonds), and the isothermality index (iso, plus signs) all have very low, almost flat I-splines (max heights ≲0.01). In other words, these thermal variables explain very little additional turnover once you’ve accounted for distance and rainfall.Key point: Spatial distance is the dominant structuring factor in these data i.e. sites further apart share markedly fewer species. After accounting for that, differences in observation effort and, to a lesser degree, seasonal rainfall still shape multisite community similarity. Temperature and seasonality metrics, by contrast, appear to have only a minor independent influence on zeta‐diversity in this landscape.
# Deviance explained summary results
with(summary(zeta2$model), 1 - deviance/null.deviance)
#> [1] 0.3295694
# [1] 0.3733073
# 0.3733073 means that approximately 37% of the variability in the response
# variable is explained by your model. This is relatively low, suggesting that the
# model may not be capturing much of the underlying pattern in the data.
# Model summary results
summary(zeta2$model)
#>
#> Call:
#> glm.cons(formula = zeta.val ~ ., family = family, data = data.tot,
#> control = control, method = "glm.fit.cons", cons = cons,
#> cons.inter = cons.inter)
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) -2.15772 0.59128 -3.649 0.000263 ***
#> temp_mean1 0.00000 2.13983 0.000 1.000000
#> temp_mean2 0.00000 1.11988 0.000 1.000000
#> temp_mean3 0.00000 1.61548 0.000 1.000000
#> iso1 -0.41087 1.61039 -0.255 0.798615
#> iso2 -0.04217 0.89248 -0.047 0.962312
#> iso3 -0.34620 1.43598 -0.241 0.809485
#> temp_wetQ1 0.00000 1.24962 0.000 1.000000
#> temp_wetQ2 -0.58101 0.98797 -0.588 0.556473
#> temp_wetQ3 0.00000 1.35706 0.000 1.000000
#> temp_dryQ1 -0.50195 1.79367 -0.280 0.779599
#> temp_dryQ2 0.00000 0.96997 0.000 1.000000
#> temp_dryQ3 0.00000 1.18512 0.000 1.000000
#> rain_dry1 -0.52046 0.74338 -0.700 0.483842
#> rain_dry2 0.00000 0.86227 0.000 1.000000
#> rain_dry3 0.00000 1.11076 0.000 1.000000
#> rain_warmQ1 0.00000 0.92368 0.000 1.000000
#> rain_warmQ2 -0.15443 0.90639 -0.170 0.864709
#> rain_warmQ3 0.00000 1.03507 0.000 1.000000
#> obs_sum1 -2.35810 0.52901 -4.458 8.29e-06 ***
#> obs_sum2 0.00000 1.31778 0.000 1.000000
#> obs_sum3 0.00000 1.85521 0.000 1.000000
#> distance1 0.00000 0.92147 0.000 1.000000
#> distance2 -0.66283 1.28674 -0.515 0.606464
#> distance3 -0.05719 2.17657 -0.026 0.979037
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for binomial family taken to be 1)
#>
#> Null deviance: 125.425 on 1999 degrees of freedom
#> Residual deviance: 84.089 on 1975 degrees of freedom
#> AIC: 137.47
#>
#> Number of Fisher Scoring iterations: 76. Uneven sampling can disguise the true drivers of biodiversity
With sampling effort (obs_sum)
included, all sites with lots of records suddenly look far more alike
than poorly sampled ones, and the climate curves flatten, and distance
drops too.
# Fit order-2 MSGDM on the presence–absence matrix and reduced covariate set
set.seed(123) # set.seed to generate exactly the same random results i.e. sam=100
zeta2_noEff = Zeta.msgdm(
grid_spp_pa[,-(1:7)], # species matrix (rows = sites, cols = spp)
# env_vars_reduced, # decorrelated environmental variables
env_vars_reduced[,-7], # without sampling effort included
grid_env[, c("centroid_lon", "centroid_lat")], # longitude & latitude (°)
# grid_env[, c("x_aea", "y_aea")], # longitude & latitude (meters)
sam = 1000,
order = 2,
distance.type = "Euclidean",
normalize = "Jaccard",
reg.type = "ispline"
)
# Extract and plot the fitted I-splines
splines_noEff = Return.ispline(zeta2_noEff, env_vars_reduced[,-7], distance = TRUE) # Without sampling effort
Plot.ispline(splines_noEff, distance = TRUE)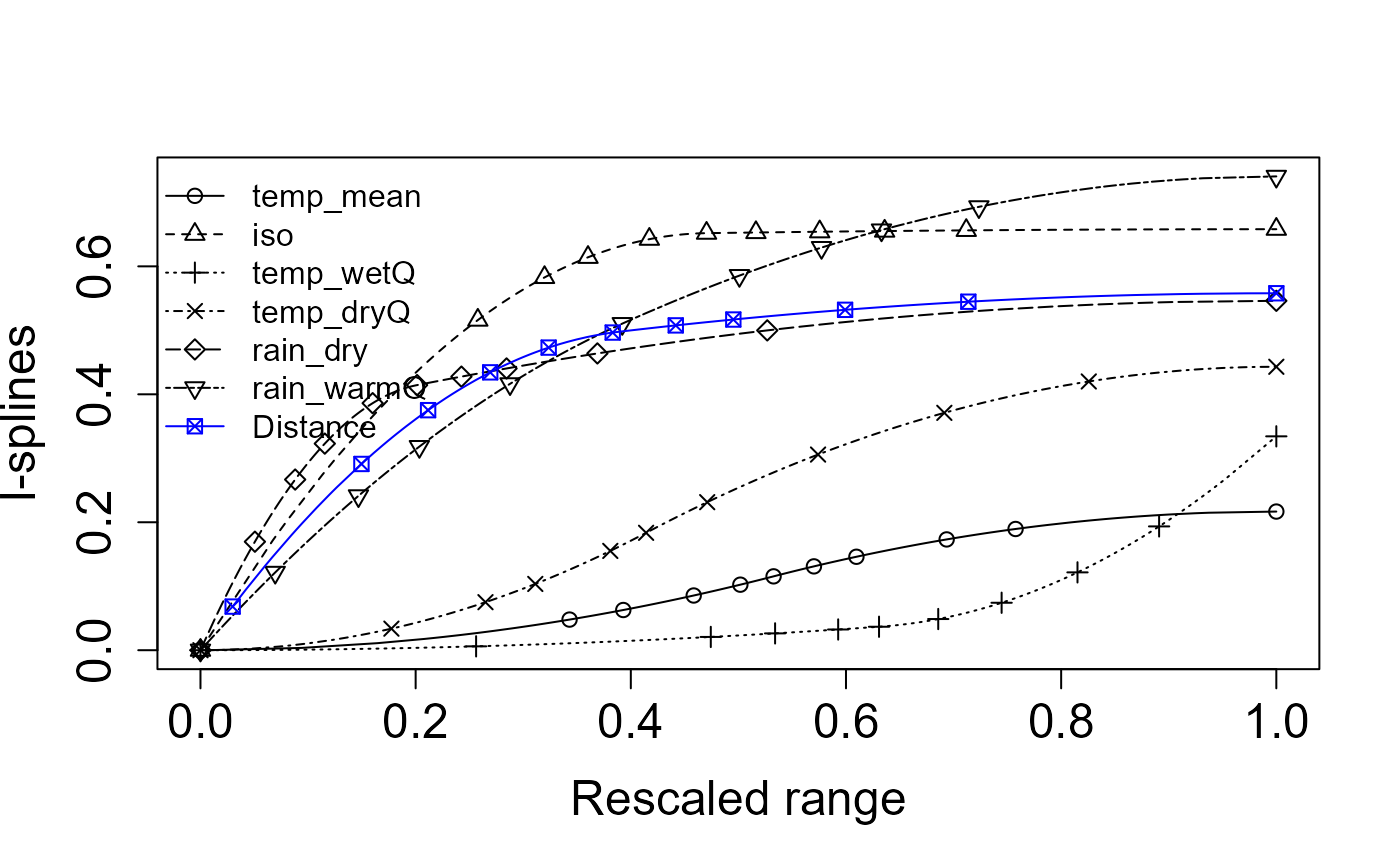
Without sampling effort (obs_sum)
temperature and rainfall curves climb high and fast: climate looks like
the main reason sites stop sharing species. Distance (blue line) still
matters, but less than several climate variables.
# Deviance explained summary results
with(summary(zeta2_noEff$model), 1 - deviance/null.deviance)
#> [1] 0.08816599
# [1] 0.09495599
# 0.09495599 means that approximately 1% of the variability in the response
# variable is explained by your model. This is relatively low, suggesting that the
# model may not be capturing much of the underlying pattern in the data.
# Model summary results
summary(zeta2_noEff$model)
#>
#> Call:
#> glm.cons(formula = zeta.val ~ ., family = family, data = data.tot,
#> control = control, method = "glm.fit.cons", cons = cons,
#> cons.inter = cons.inter)
#>
#> Coefficients:
#> Estimate Std. Error z value Pr(>|z|)
#> (Intercept) -2.30749 0.71576 -3.224 0.00126 **
#> temp_mean1 0.00000 2.72985 0.000 1.00000
#> temp_mean2 -0.21672 1.53696 -0.141 0.88787
#> temp_mean3 0.00000 2.36184 0.000 1.00000
#> iso1 -0.64639 2.07603 -0.311 0.75553
#> iso2 -0.01169 1.34429 -0.009 0.99306
#> iso3 0.00000 1.69884 0.000 1.00000
#> temp_wetQ1 0.00000 1.60974 0.000 1.00000
#> temp_wetQ2 -0.05815 1.34254 -0.043 0.96545
#> temp_wetQ3 -0.27615 1.87980 -0.147 0.88321
#> temp_dryQ1 0.00000 2.14957 0.000 1.00000
#> temp_dryQ2 -0.44304 1.37079 -0.323 0.74654
#> temp_dryQ3 0.00000 1.72340 0.000 1.00000
#> rain_dry1 -0.38117 1.08562 -0.351 0.72550
#> rain_dry2 -0.16497 1.26607 -0.130 0.89633
#> rain_dry3 0.00000 1.74241 0.000 1.00000
#> rain_warmQ1 -0.36204 1.24736 -0.290 0.77163
#> rain_warmQ2 -0.37857 1.35207 -0.280 0.77948
#> rain_warmQ3 0.00000 1.55813 0.000 1.00000
#> distance1 -0.45944 1.26391 -0.364 0.71622
#> distance2 -0.09850 1.62880 -0.060 0.95178
#> distance3 0.00000 2.50094 0.000 1.00000
#> ---
#> Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
#>
#> (Dispersion parameter for binomial family taken to be 1)
#>
#> Null deviance: 65.233 on 999 degrees of freedom
#> Residual deviance: 59.482 on 978 degrees of freedom
#> AIC: 106.61
#>
#> Number of Fisher Scoring iterations: 7With sampling effort removed the model explains only ≈ 8% of the deviance, compared to 37%. In other words, after discounting chance, less than one-tenth of the variation in shared-species counts is captured by climate and distance alone, confirming that survey effort had been the primary driver of the much higher explanatory power in the full model.
Key point: Uneven sampling can hide the real drivers of biodiversity. Without accounting for effort, the model attributes most turnover to climate. Adding effort shows that well-surveyed sites appear more similar simply because thorough searches record more species, while lightly sampled sites miss many and seem distinct. Correcting for effort is essential; only then can we see how climate and distance truly shape species turnover.