dissmapr
A Novel Framework for Automated Compositional Dissimilarity and Biodiversity Turnover Analysis
1. Automated Ispline Modeling & Visualization
To streamline the exploration of multi‐site turnover drivers, we now introduce an automated sub-workflow that fits, extracts and visualizes I-spline models for any set of zeta orders in just three function calls. Rather than manually looping over orders, binding tables, and crafting bespoke plots, you can:
-
Run and combine all ispline GLMs via
run_ispline_models(), which:>- Calls
Zeta.msgdm()for each order of interest (e.g. ζ₂…ζ₆) - Extracts both the raw covariates (including geographic distance) and their spline bases
- Returns one tidy tibble tagged by
zOrder, ready for plotting or further analysis
- Calls
-
Inspect partial-dependence curves with
plot_ispline_lines(), which:>- Automatically locates the spline column matching any chosen
covariate (e.g. “dist” →
dist_is) - Draws each zeta-order’s I-spline curve with thin lines
- Overlays small markers at user-specified quantiles of the raw predictor and a larger symbol at each curve’s minimum
- Automatically locates the spline column matching any chosen
covariate (e.g. “dist” →
-
Summarize overall variation using
plot_ispline_boxplots(), which:- Detects every
_isspline column in your data - Pivots to long format and produces facetted boxplots for each term
- Applies a color-blind–safe Viridis palette with independent scales per facet
- Detects every
By packaging these steps into self-documented functions, we embed ispline modeling and visualization into our RMarkdown workflow with a single, transparent call. The parameters (orders, covariate name, colors, shapes, etc.) are fully customizable, while sensible defaults minimize boilerplate, ensuring reproducibility, readability and ease of maintenance in automated biodiversity turnover analyses.
2. Fit and combine ispline models
The following chunk uses our run_ispline_models() helper
to fit Zeta.msgdm(reg.type = “ispline”) for orders 2–6,
extract both raw covariates (including distance) and their spline bases,
and bind everything into one tidy table tagged by
zOrder.
# Fit & gather ispline outputs for orders 2:6
set.seed(123) # set.seed to generate exactly the same random results i.e. sam=100
ispline_gdm_tab = run_ispline_models(
spp_df = grid_spp_pa[,-(1:7)],
env_df = env_vars_reduced,
xy_df = grid_env[, c("centroid_lon", "centroid_lat")],
orders = 2:6,
sam = 100, # Set really low to run fast
normalize = "Jaccard",
reg_type = "ispline"
)
str(ispline_gdm_tab, max.level=1)
#> List of 2
#> $ zeta_gdm_list:List of 5
#> $ ispline_table:'data.frame': 500 obs. of 17 variables:
ispline_tabs_all = ispline_gdm_tab$ispline_table
head(ispline_tabs_all)
#> temp_mean iso temp_wetQ temp_dryQ rain_dry rain_warmQ obs_sum
#> 1 0.0000000 0.000000000 0.000000000 0.00000000 0.00000000 0.00000000 0
#> 2 0.2451464 0.008274168 0.002209801 0.07613776 0.00000000 0.01288720 0
#> 3 0.3436462 0.097618945 0.033482426 0.08260041 0.01133362 0.01498400 0
#> 4 0.3528630 0.114123234 0.035916031 0.09057801 0.01292128 0.02134323 0
#> 5 0.3636917 0.119986685 0.062552912 0.13104450 0.01443688 0.02992775 0
#> 6 0.3686409 0.121759622 0.085519127 0.14153534 0.01485122 0.03148699 0
#> distance temp_mean_is iso_is temp_wetQ_is temp_dryQ_is rain_dry_is
#> 1 0.03214127 0.00000000 0 0 0.005488865 0.1058544
#> 2 0.03214127 0.01574585 0 0 0.044501447 0.1058544
#> 3 0.04545457 0.03094128 0 0 0.047455865 0.1800223
#> 4 0.09642380 0.03262326 0 0 0.051025806 0.1901065
#> 5 0.09642380 0.03465627 0 0 0.067823321 0.1996631
#> 6 0.10163911 0.03560591 0 0 0.071820515 0.2022638
#> rain_warmQ_is obs_sum_is distance_is zOrder
#> 1 0.00000000 0 0.2100488 Order2
#> 2 0.02205003 0 0.2100488 Order2
#> 3 0.02557608 0 0.2924598 Order2
#> 4 0.03616458 0 0.5830938 Order2
#> 5 0.05020686 0 0.5830938 Order2
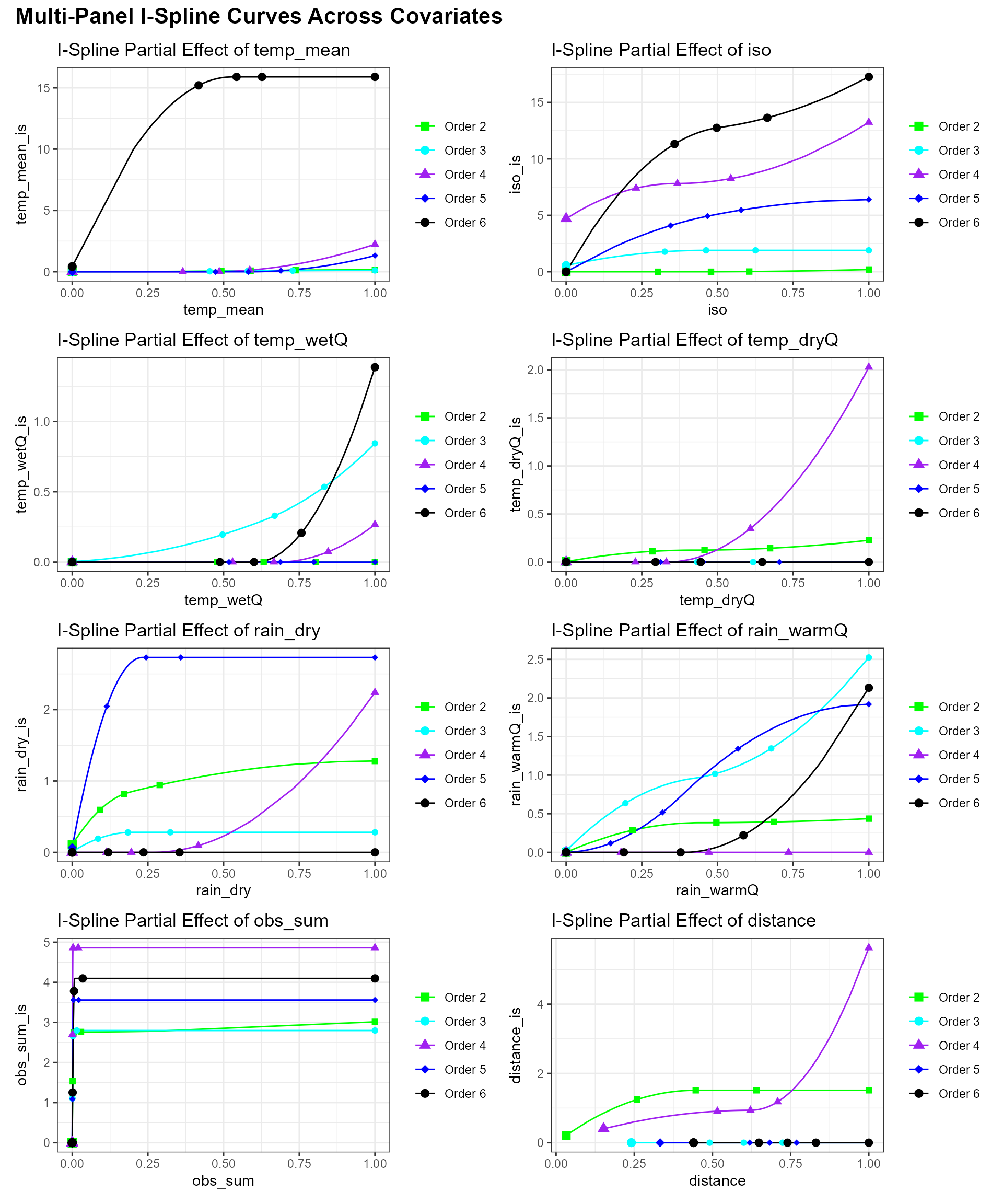
#> 6 0.05272641 0 0.6106080 Order23. Plot Partial‐Dependence Curves for All Covariates
Here we produce a unified, multi‐panel display of each predictor’s
I‐spline partial‐dependence curve using our
plot_ispline_lines() helper. That function will:
- Auto‐detect the spline column for each covariate (e.g. “dist” →
dist_is). - Draw a thin line for each zeta‐order.
- Mark selected quantiles along the raw covariate with small symbols.
- Highlight each curve’s minimum value with a larger marker.
We then loop over all raw covariates (those ending in
_is), generate a separate plot per variable, and assemble
them into a cohesive multi‐panel layout using the patchwork
package. This makes it possible to compare turnover responses across the
full suite of environmental drivers.
# 1. Identify all raw covariates with a spline term
raw_vars = sub("_is$", "",
grep("_is$", names(ispline_tabs_all), value = TRUE))
# 2. Generate one plot per covariate
plots = lapply(raw_vars, function(var) {
plot_ispline_lines(
ispline_data = ispline_tabs_all,
x_var = var,
orders = paste("Order", 2:6),
cols = c('green','cyan','purple','blue','black'),
shapes = c(15,16,17,18,19)
) +
ggtitle(paste("I-Spline Partial Effect of", var))
})
# 3. Combine into a grid (2 columns here; adjust ncol as needed)
wrap_plots(plots, ncol = 2) +
plot_annotation(
title = "Multi-Panel I-Spline Curves Across Covariates",
theme = theme(plot.title = element_text(size = 16, face = "bold"))
)
# # Simle single covariate line plot for "dist"
# plot_ispline_lines(
# ispline_data = ispline_tabs_all,
# x_var = "dist",
# orders = paste("Order", 2:6),
# cols = c('green','cyan','purple','blue','black'),
# shapes = c(15,16,17,18,19)
# )Ecological Interpretation and Conservation
Implications
Which predictors drive turnover shifts with the number of sites:
* Two‐sites: Distance dominates. Shared species drop
off steeply as sites become farther apart.
* Three‐sites: Isothermality (stable day–night
vs. seasonal temperature swings) is most important, suggesting
communities in areas with steady daily temperatures stay more
similar.
* Four‐sites: Mean temperature and wet‐quarter
temperature have the strongest effects, indicating thermal limits filter
species across moderate clusters of sites.
* Five‐sites: Sampling effort peaks in influence,
warning that uneven survey intensity can masquerade as real ecological
turnover at this scale.
* Six‐sites: Rainfall variables—especially warm‐quarter
and dry‐season rainfall—become the key filters, showing that moisture
availability during extreme seasons governs species overlap in larger
site groups.
Key point: At the smallest scale, dispersal barriers (distance) set the stage for which species can overlap. As you expand to three, four or more sites, environmental filters—first thermal, then hydric—sequentially take over. This scale‐dependent shift reveals that different ecological processes dominate community assembly at different spatial extents, with direct implications for how we design surveys and target conservation under changing climates.
4. Facetted boxplots of all spline terms
Finally, we summarize the distribution of every _is basis across
orders using plot_ispline_boxplots(). Each spline term is
facetted with free scales, and fills are mapped to zOrder via a
color-blind–friendly Viridis palette.
# Facetted boxplots of all *_is columns
plot_ispline_boxplots(
ispline_data = ispline_tabs_all,
ispline_suffix = "_is",
order_col = "zOrder",
palette = "viridis",
direction = -1,
ncol = 3
)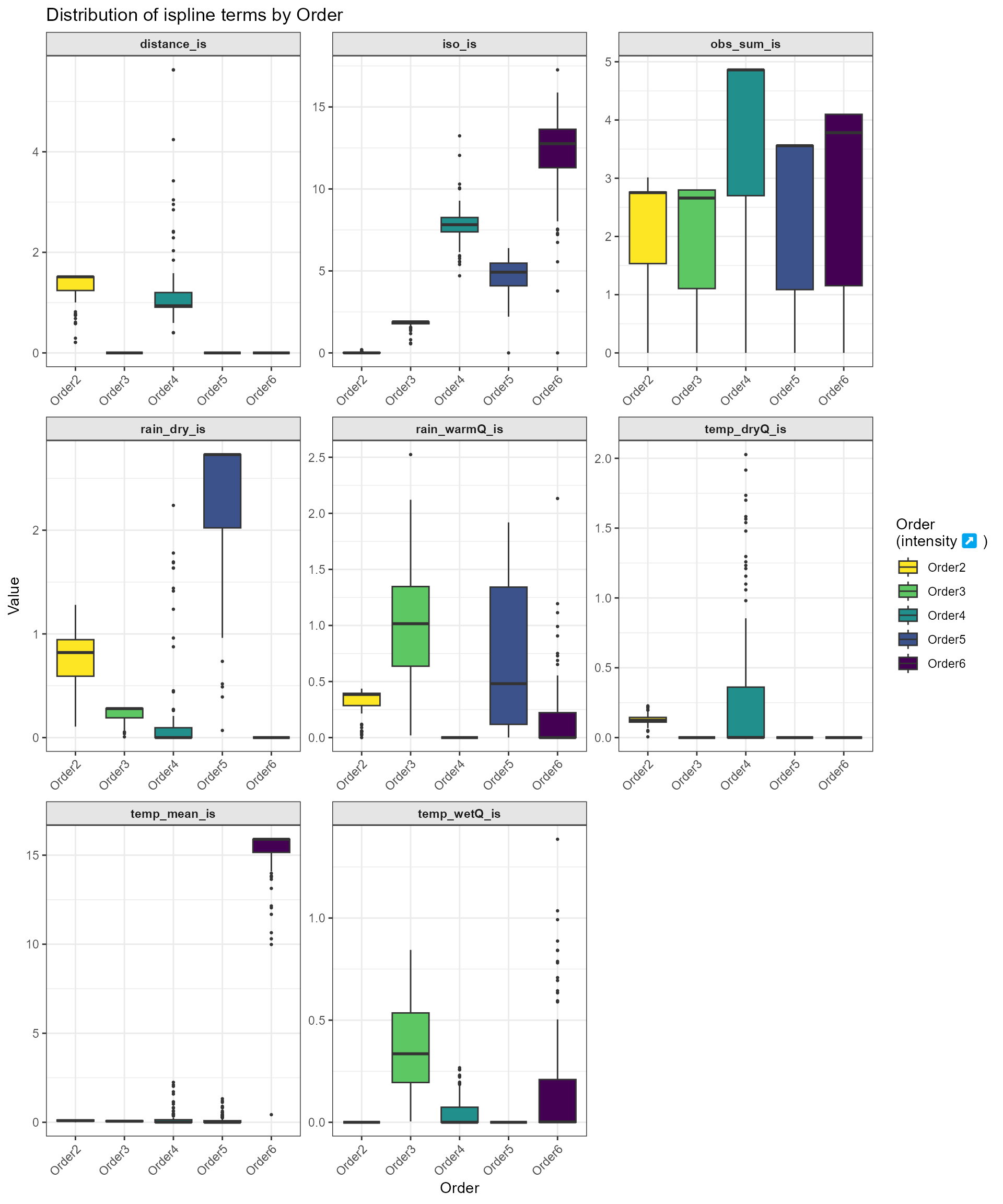
Ecological Interpretation and Conservation
Implications Which factors matter depends on how many sites you
compare at once:
- Two sites: Geographic distance dominates. Nearby
sites share many species, distant sites very few.
- Three sites: Isothermality (day–night versus seasonal
swings) has its strongest effect, suggesting that stable daily
temperatures support more consistent communities.
- Four sites: Temperature (mean and seasonal highs)
becomes the key driver, indicating that thermal limits filter which
species can persist across moderate clusters.
- Five sites: Dry-season rainfall peaks in importance,
showing that moisture availability determines whether species can
survive across larger groups.
- Four sites (again): Sampling effort bias is highest,
meaning uneven survey intensity can look like an ecological signal at
this scale.
Key points:
- At small scales (two sites), where species must
actually move between locations, distance is the main barrier to sharing
species.
- At medium scales (three to five sites), local climate
steps in: only species that can tolerate the same temperature and
moisture levels hang on across multiple sites.
- Breaking up habitat makes it even harder for species to move, while
hotter, drier conditions shrink the range where they can survive—driving
faster loss of biodiversity.
- Protecting connected corridors and a variety of microclimates helps
species disperse and find refuge, slowing turnover and preserving the
common “backbone” species that keep ecosystems stable and healthy.